2022年5月23日,生物信息学专业期刊Briefings In Bioinformatics在线发表了中国科学院上海营养与健康研究所的研究成果“MultiWaverX: Modeling latent sex-biased admixture history ”
2022年5月23日,生物信息学专业期刊Briefings In Bioinformatics在线发表了中国科学院上海营养与健康研究所的研究成果“MultiWaverX: Modeling latent sex-biased admixture history ”。该项工作提出了一种新方法MultiWaverX,可推断人群性别偏向性混合历史,并应用该方法分析和重构了中亚地区、中东地区以及美洲大陆的17个人群的性别偏向性基因交流历史。
性别偏向性实际上广泛存在于人群基因交流过程中,即特定祖源的男女遗传贡献存在差异。非裔美国人(African Americans)和拉丁裔美洲人(Hispanic Americans or Latino American)为学界熟知的存在性别偏向性混合的人群。性别偏向性混合的研究对了解人群形成和演化历程、理解现代人类遗传差异、以及指导医学研究都有重要的理论意义和应用价值。然而,受限于分析方法,人群演化历史上错综复杂的基因交流中存在的性别偏向性长期以来未得到充分研究,特别是一些经历过多次而复杂基因交流历史的人群,曾经发生的不同方向的性别偏向混合往往被忽视。MultiWaverX的提出在很大程度上为这些问题的解决提供了新方法和新思路。
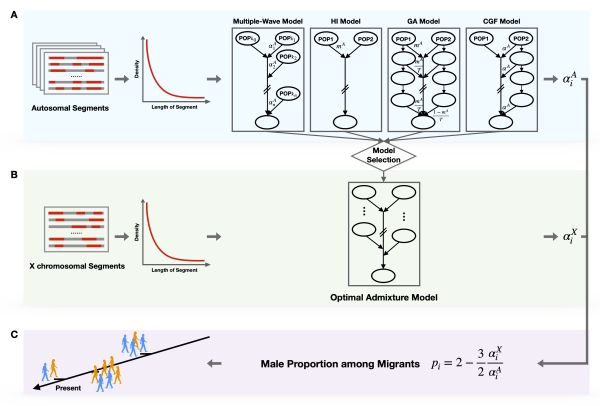
图 1. MultiWaverX 算法流程图
MultiWaverX是在研究团队前期提出的算法MultiWaver基本模型和方法的基础上进一步发展而来,特别是植入了性别偏向性混合历史推断模块。其具体算法可以分为以下三个步骤(图1):(1)基于常染色体的祖先片段长度分布信息,利用最大期望算法(EM algorithm)或二分搜索算法(Binary Search algorithm)估计不同混合模型下混合时间和常染色体混合比例等参数,进而利用似然比检验(Likelihood ratio test)或贝叶斯信息准则(Bayes Information Criterion)选择最优混合模式。(2)在第一步确定的混合模式下,基于X染色体的祖先片段长度分布信息估计X染色体的混合比例。(3)针对每个祖先人群的每波混合事件,结合常染色体和X染色体的混合比例计算男性贡献比例,从而判断性别偏向性方向以及程度。相比于传统方法,MultiWaverX有如下两个优势:首先,该方法可以准确地估计混合波数以及每波混合事件的混合时间、混合比例和性别偏向性混合参数,为后续性别偏向混合历史的精细化重构打下基础;其次,该方法充分利用常染色体与X染色体共享历史事件的规律,通过数据量相对更丰富的常染色体推断人群混合模式,进而估计性别偏向性参数,可以有效克服由于X染色体较短,数据量较小带来的模型推断不稳定的缺陷。系统的模拟验证数据表明,MultiWaverX在不同混合模式下估计性别偏向性参数均有较高的准确性,在应对各类数据噪声时也表现出一定的稳健性。此外,研究团队依据混合过程中特定祖先人群男性贡献比例的变化趋势,进一步将性别偏向性混合模型归纳为以下五种(图2):稳定模型(steady model)、增强模型 (enhanced model)、减弱模型(dilution model)、波动模型(turnover model)、抵消模型(cancellation model)。其中,性别偏向抵消模型最为特殊,性别偏向信号在经历多次方向相反的混合事件后得以抵消。研究团队在分析实际数据时,发现中国西北少数民族哈萨克族是该混合模型的代表人群。哈萨克族主要居住于中国西北地区,其主要遗传成分来自东亚和欧洲祖先人群,且混合比例比在常染色体和X染色体水平上均为60:40,若使用传统方法进行推断,结果均为无性别偏向混合。而通过MultiWaverX分析,研究团队发现该人群呈现出早期欧洲男性为主(约3000年前),近期东亚男性为主(约750年前)的两波性别偏向性混合历史。