

-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
人工智能研究院杨耀东助理教授团队在RLHF技术方向研究取得重大进展
【字体: 大 中 小 】 时间:2023年04月13日 来源:北京大学人工智能研究院
编辑推荐:
近日,北京大学人工智能研究院多智能体中心杨耀东助理教授团队在NeurIPS 2022发表论文“Meta-Reward-Net: Implicitly Differentiable Reward Learning for Preference-based Reinforcement Learning”。该工作提出了一个反馈高效的偏好强化学习(Preference-based Reinforcement Learning,PbRL)算法Meta-Reward-Net(MRN),MRN能够在学习奖励函数的同时关注Q函数的表现。实验证明了所提出算法的有效性,在少量人类偏好的情况...

近日,北京大学人工智能研究院多智能体中心杨耀东助理教授团队在NeurIPS 2022发表论文“Meta-Reward-Net: Implicitly Differentiable Reward Learning for Preference-based Reinforcement Learning”。该工作提出了一个反馈高效的偏好强化学习(Preference-based Reinforcement Learning,PbRL)算法Meta-Reward-Net(MRN),MRN能够在学习奖励函数的同时关注Q函数的表现。实验证明了所提出算法的有效性,在少量人类偏好的情况下,MRN能够比之前的方法学到更加准确的Q函数和更好的策略。
自2022年11月发布以来,ChatGPT[1]在全球掀起了轩然大波。仅仅两个月的时间,月活跃用户就已经达到了1亿,创造了全新的用户增长速度纪录。在ChatGPT中,OpenAI的研究者采用了人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)技术,通过训练奖励函数对模型进行微调,从而使其生成的内容更符合人类价值观。如图1所示,ChatGPT在步骤2中使用经过人类排序的回答数据训练奖励函数(Reward Function),随后在步骤3中利用该奖励函数微调(Fine-tune)模型。值得一提的是,在OpenAI最新发布的GPT-4[2]中,我们仍然可以看到RLHF技术的身影。
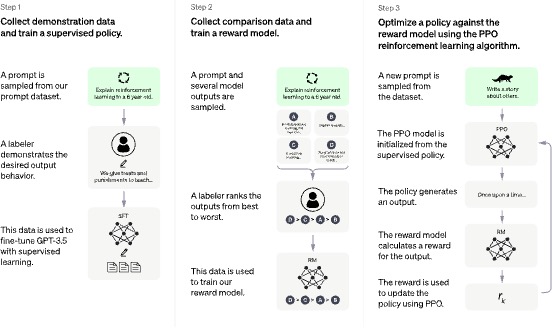
图1 ChatGPT框架图[1],其中步骤2使用了RLHF技术训练奖励函数
除了在ChatGPT等模型中展现出强大的威力,RLHF技术在强化学习任务中也发挥着重要作用。在常见的决策任务中,智能体的目标是最大化累积回报。然而,强化学习的一个核心挑战是如何设计奖励函数。一方面,奖励函数的质量在很大程度上取决于问题解决者对任务目标、操作逻辑和相关背景知识的理解。另一方面,智能体可能会通过破解奖励函数,而不是真正解决目标任务,来最大化累积奖励。此外,在一些涉及人类的场景中,智能体的目标是最大化人类的满意度,但是指定奖励函数往往非常困难。RLHF技术可以通过监督学习的方法学习到与人类反馈相一致的奖励函数,从而可以将奖励与人类价值观直接对齐。如图2所示,人类专家为智能体的轨迹提供人类反馈,从而可以通过人类反馈学习奖励函数,并通过预测的奖励学习强化学习策略。
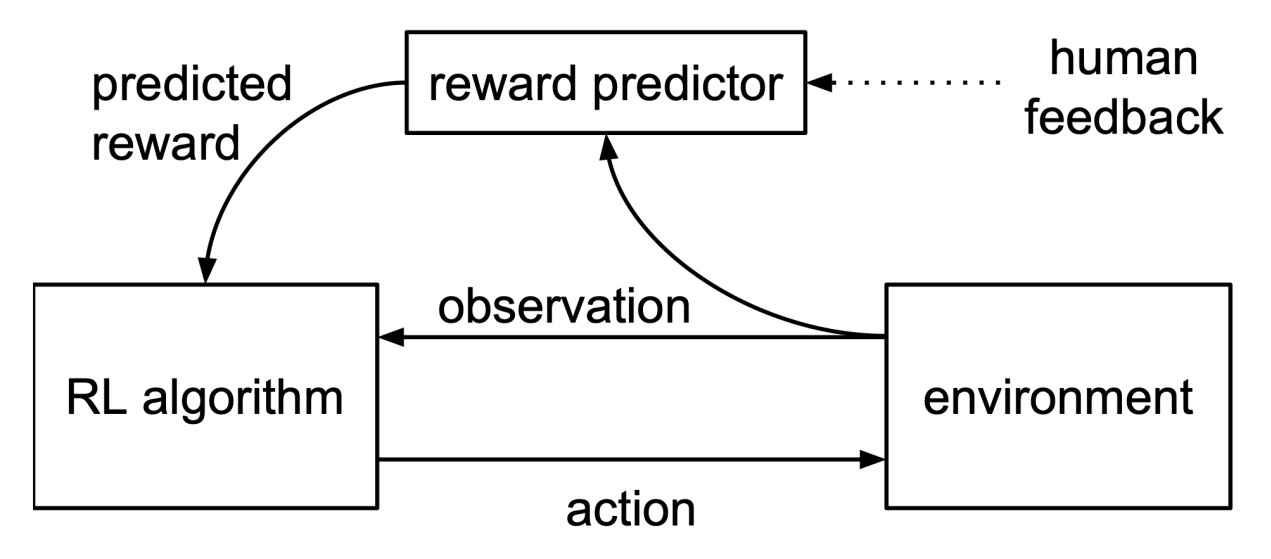
图2 RLHF框架图[3]
然而,反馈效率一直是RLHF算法的一个瓶颈。反馈效率指的是如何在有限的人类反馈下最大化学习效果。由于人类专家标注的偏好数据通常是比较昂贵的,现有方法往往需要较多的人类反馈进行学习,因此反馈效率较低。此外,之前的RLHF算法只通过人类偏好学习奖励函数,因此当人类反馈较少时,RLHF算法学习出的奖励函数是不准确的,进而影响Q函数和策略的学习。这一现象被称为确认偏差(Confirmation Bias),即一个神经网络过拟合到了另一个神经网络不准确的输出。
本工作关注RLHF算法的反馈效率问题。考虑到奖励函数和Q函数的作用关系,我们提出了一个教师-学生的教学方法,以更好地利用有限的人类反馈。我们将奖励函数视为教师网络,将Q函数视为学生网络,在学习奖励函数的同时,额外关注Q函数的表现。我们使用双层优化方法(Bi-level Optimization)建模整个过程,算法框架如图3所示。具体来说,在内层循环中,MRN通过奖励函数更新Q函数和策略;在外层循环中,MRN根据Q函数在偏好数据上的评估损失优化奖励函数。这样奖励函数在通过人类反馈学习的同时,可以额外关注Q函数的准确性,从而提高反馈效率。
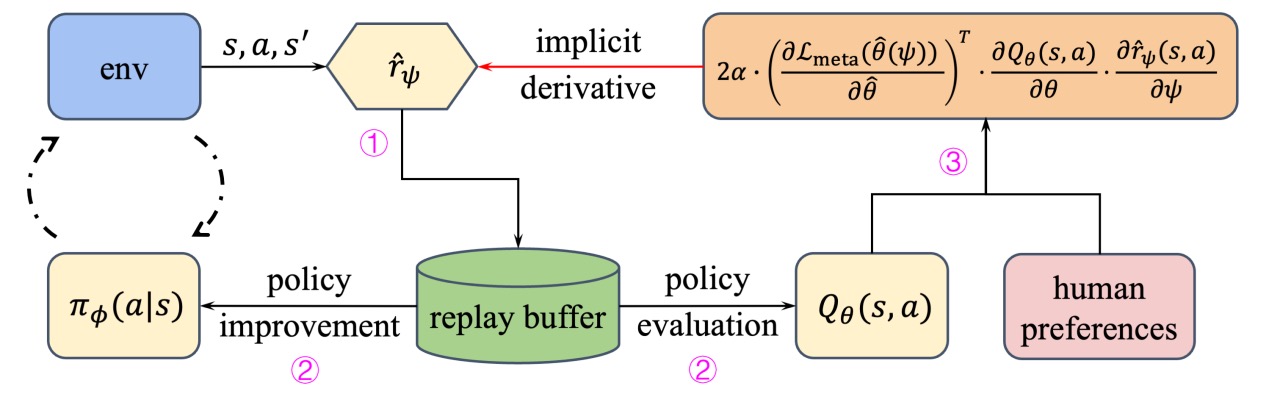
图3 MRN算法框架。①策略与环境交互时会采集数据,奖励函数会对数据标注奖励标签。②策略和Q函数使用由最新的奖励函数标注的数据进行学习。③使用Q函数在偏好数据上做测试,为奖励函数学习提供隐式梯度。
然而,由于Q函数和奖励函数的参数之间没有显式关系,MRN首先采用伪更新的方法建立了Q函数与奖励函数的关系,具体来说,MRN算法利用奖励函数的输出来对拷贝的Q函数进行一步更新,并用拷贝的Q函数在人类反馈数据上进行测试,计算损失。根据链式法则,该损失可以用于对奖励函数计算隐式梯度,从而更新奖励函数的参数,使其在学习人类反馈的同时,关注Q函数的表现。
此外,本工作对MRN算法的收敛性进行了分析。MRN通过双层优化框架进行建模,涉及外层损失和内层损失,定理1和定理2分别对外层、内层损失进行了分析。定理1证明了MRN算法的外层损失在一些温和条件下的收敛速率。在相同条件下,定理2证明了MRN算法内层损失的收敛性。

图4 MRN算法的收敛性分析
为了评估MRN算法是否有效地提高了反馈效率,本工作在Meta-world[4]的六个机器人操纵任务和DeepMind Control Suite(DMControl)[5,6]的三个智能体移动任务上进行了实验评估。
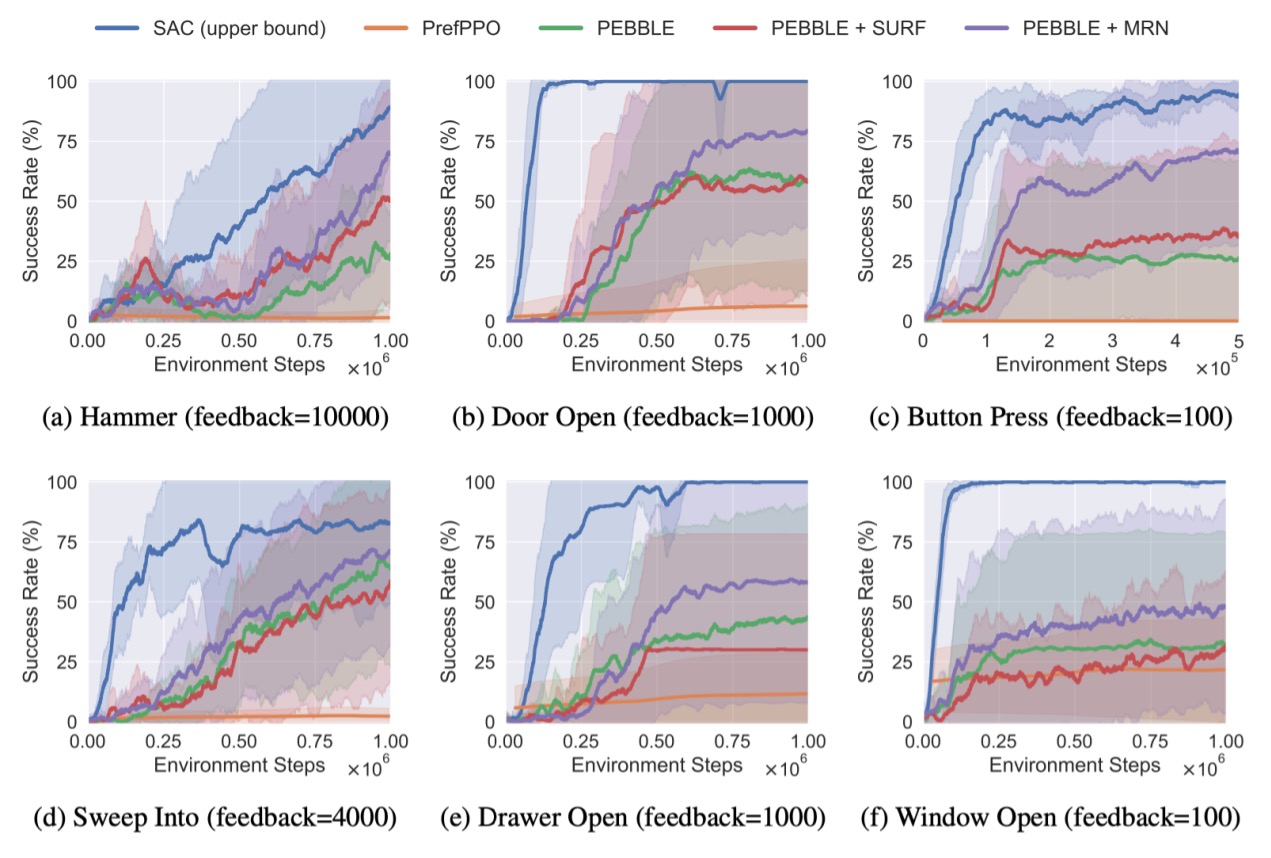
图5 Meta-world六个任务的训练曲线,实线和阴影分别表示10个种子的均值和标准差
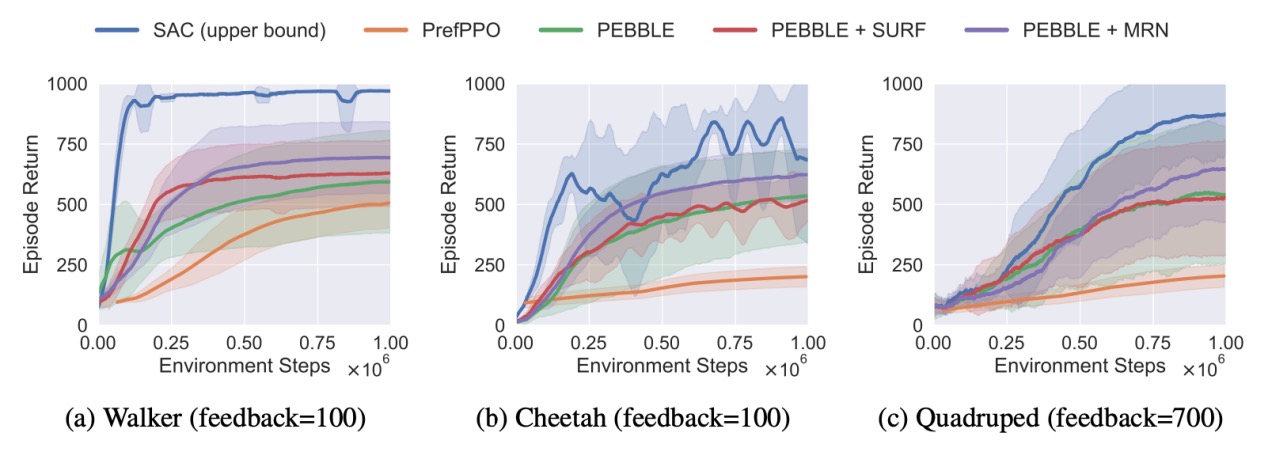
图6 DMControl三个任务的训练曲线,实线和阴影分别表示10个种子的均值和标准差
图5和图6展示了MRN和其他基线方法的训练曲线。在图中,由于使用真实奖励函数进行学习,SAC(蓝线)在所有任务中表现最好,作为所有RLHF方法的上界。由于提供的反馈较少,所有RLHF方法与SAC上界之间存在差距,但MRN仍然在很大程度上超过了RLHF基线。实验结果表明,MRN显著提高了RLHF算法的反馈效率。
本工作提出了一种反馈高效的偏好强化学习方法MRN,在学习奖励函数的同时,将Q函数与人类偏好对齐,从而可以学习到更准确的Q函数。实验证明了当人类反馈较少时,MRN超越了之前的RLHF方法,并显著提高了各种机器人模拟任务的反馈效率。当人类反馈很少时,MRN大大超越了RLHF基线方法。
未来,RLHF算法仍有许多值得探究的方向:例如如何进一步提高RLHF算法的反馈效率,如何只使用很少的人类反馈即可学习到优异的策略,如何有效地将RLHF算法拓展到图像输入的强化学习任务上,以及如何更加鲁棒地从含有噪声的人类反馈中进行学习。
参考文献:
[1] OpenAI. Openai: Introducing ChatGPT, 2022. URL https://openai.com/blog/chatgpt.
[2] OpenAI. Gpt-4 technical report, 2023. arXiv preprint arXiv:2303.08774.
[3] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems (NeurIPS), 2017.
[4] Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning (CoRL), volume 100, pages 1094–1100. PMLR, 2020.
[5] Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018.
[6] Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, Nicolas Heess, and Yuval Tassa. dm_control: Software and tasks for continuous control. Software Impacts, 6:100022, 2020.
下载安捷伦电子书《通过细胞代谢揭示新的药物靶点》探索如何通过代谢分析促进您的药物发现研究
10x Genomics新品Visium HD 开启单细胞分辨率的全转录组空间分析!
生物通微信公众号


知名企业招聘
今日动态 | 人才市场 | 新技术专栏 | 中国科学人 | 云展台 | BioHot | 云讲堂直播 | 会展中心 | 特价专栏 | 技术快讯 | 免费试用
版权所有 生物通
Copyright© eBiotrade.com, All Rights Reserved
联系信箱:
粤ICP备09063491号












